
相关影像



快速介绍
索尼公司知道,3D 硬件的开发可能会非常麻烦。 因此,他们的首款游戏机将保持简单且实用的设计…… 尽管这可能需要付出代价!
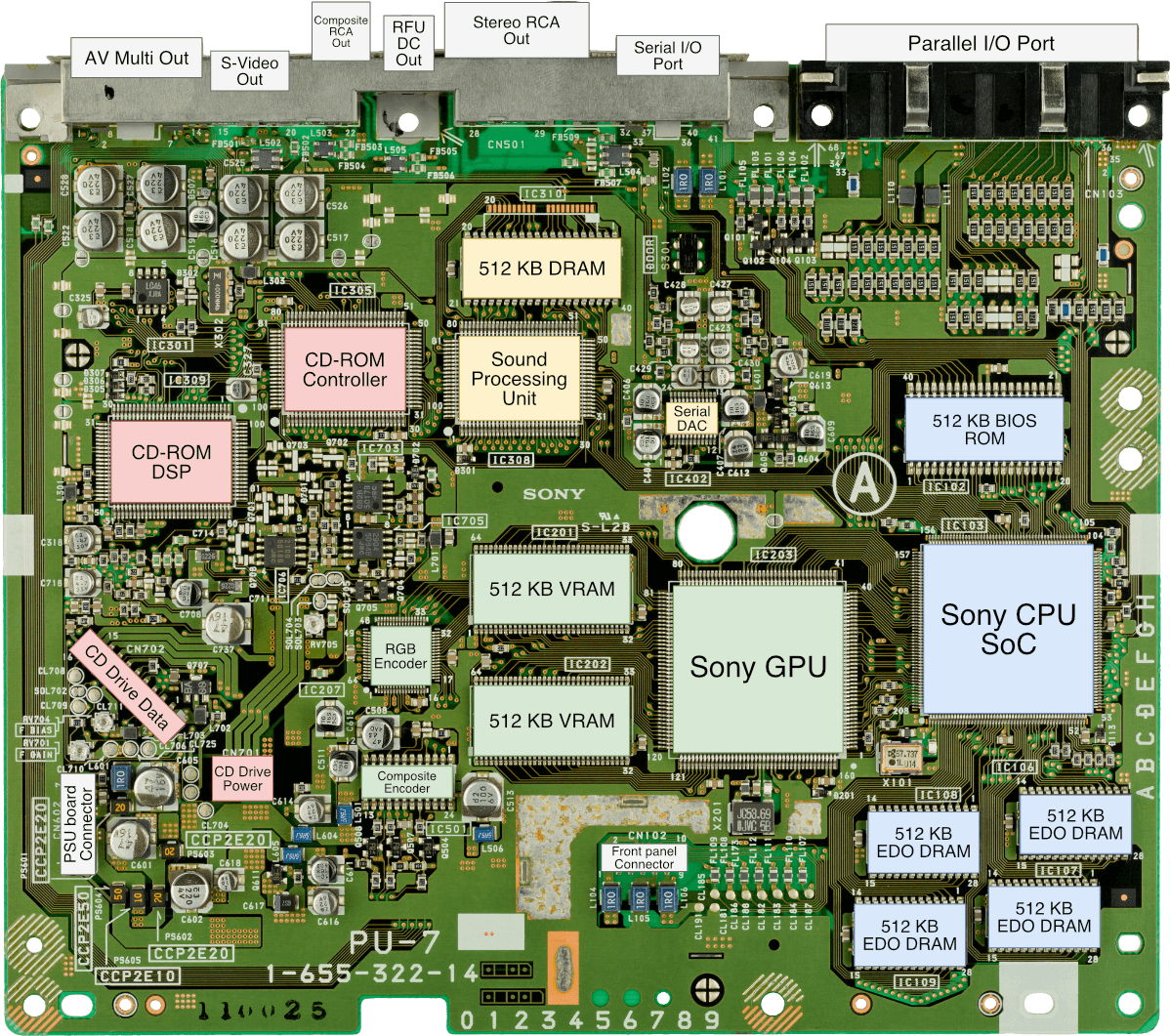
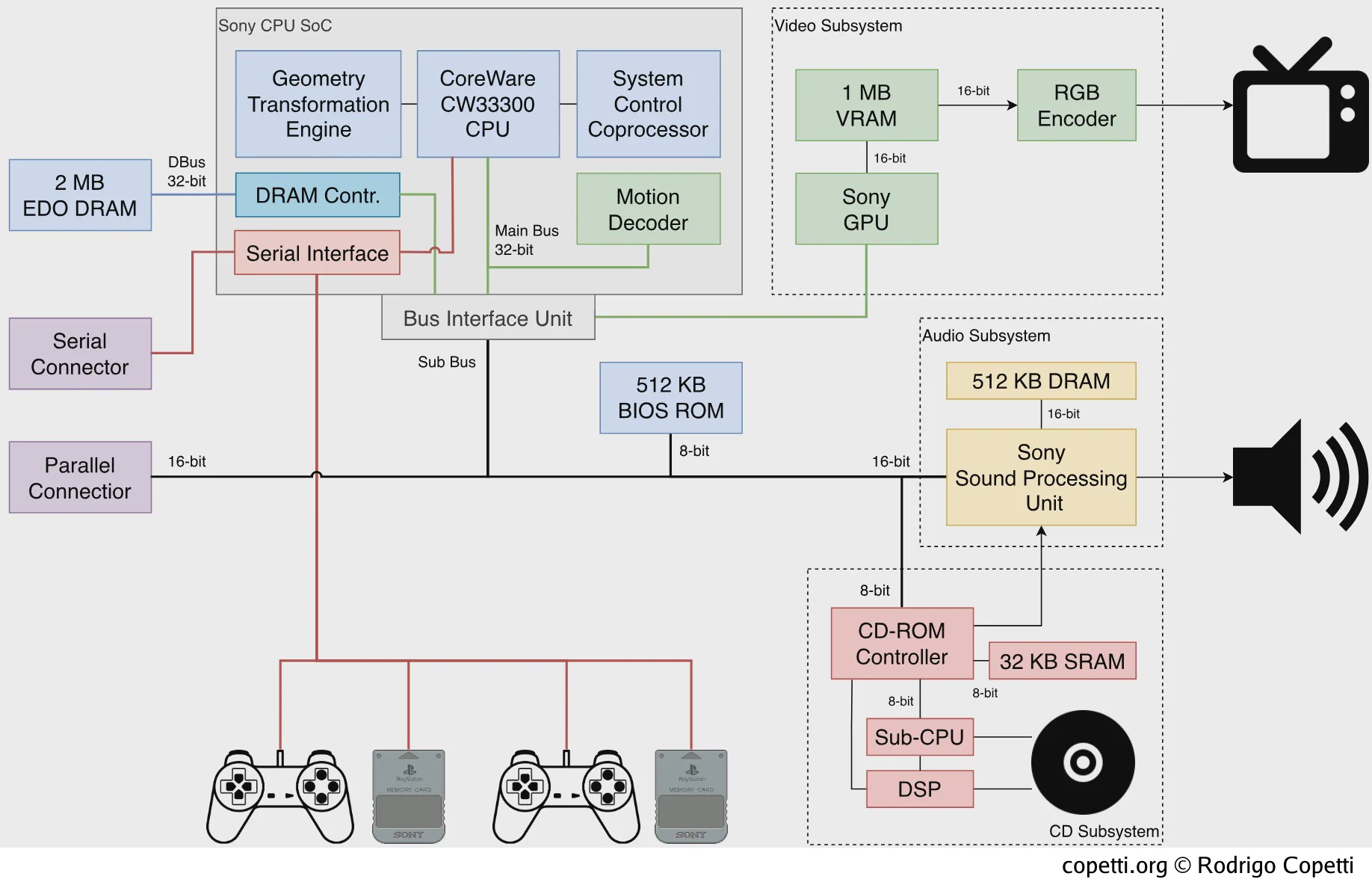
中央处理器 (CPU)
本节将对索尼CXD8530BQ进行剖析,它是这款游戏机的两大芯片之一。 在当今世界,我们称之为“片上系统”(System-on-Chip,SoC)。
起源
主处理器是一种“由y设计、基于z并从w处二次采购”的产品,这用几句话来概括有点过于冗长,所以我们何不从一些历史背景开始呢?
一点历史

九十年代初,许多流行 CPU 的命运发生了变化。 曾经领先的8位CPU(如Z80和6502)已不再受人关注,而摩托罗拉著名的68000以及其他在80年代末获得成功的16位设计已成为取代它们的候选产品。 即使在此时的个人电脑领域,塔能鲍姆(A.S.Tanenbaum)在与托瓦兹(L.Torvalds)辩论的著名辩论中,也只给了英特尔的x86架构五年的时间到它退出家用市场。
初看起来,技术发展似乎在此时遇到了障碍。 但实际上,新一轮相对陌生的CPU浪潮正在涌入主流设备。 其中许多设计都源于学术界,因此是为了证明特定的设计理念而存在的。 那个时代的新型CPU包括:
- MIPS: 由硅谷图形(Silicon Graphics Incorporated, SGI)采用(针对图形工作站)。
- PowerPC: 被苹果公司采用(针对台式机发行)。
- SPARC:由太阳微系统(Sun Microsystems)创造(针对服务器和商务工作站)。
- ARM:由Acorn公司创造(最初面向消费市场,后来转向PDA和手机)。
- ……还有许多“微控制器”芯片尚未定型或被任何行业采用,如日立的SH或NEC的V810。 出乎他们意料的是,这些芯片后来分别被世嘉土星和任天堂Virtual Boy选用。
所有这些处理器都有一个共同点:它们都遵循精简指令集计算机(RISC)规则,这从根本上改变了这些芯片的设计和编程方式。 RISC CPU的一条规则规定,单条指令不能混合内存和寄存器操作,这样硬件设计人员就可以简化执行指令的电路……然后利用并行技术对其进行增强。
MIPS和索尼

MIPS 计算机系统公司起源于其创始人(斯坦福大学教师)将其研究成果转化为物理处理器的迫切愿望,80年代硅谷的风投资本家也急于投资于此[2]。 他们首次推出的中央处理器“MIPS R2000”被认为是第一个采用RISC设计的商用中央处理器;它在许多UNIX工作站中都占有一席之地。
然而,直到 1987 年,MIPS的芯片才成为人们谈论的话题,原因是它被SGI公司采用(且后来被收购),为其设备提供动力。 SGI是计算机图形市场上极具影响力的创新者,尤其是在硬件加速顶点流水线的开发方面,而顶点流水线的任务最初是由软件(CPU内部)完成的。 收购之后,SGI 在CPU和图形领域都占据了领先地位。
在开发 PlayStation 之前,MIPS 转而采用基于IP许可的商业模式,即以许可的形式出售其CPU设计,然后由被许可方自由定制和生产设计。 他们提供的部分产品包括R3000A CPU,它出现在他们的低端产品目录中。 因此,R3000A并不属于旗舰产品系列(不像另一家后来采用的R4000),但就成本而言,它是一项极具吸引力的投资。
回到正题,索尼自行设计了音频和图形芯片,但他们仍然需要能够驱动这两种芯片的领先芯片。 所选的CPU必须足够强大,以展示索尼芯片令人印象深刻的性能,同时价格也要合理,以保持游戏机的价格竞争力。
LSI和委托
与此同时,LSI Logic(一家半导体制造商)是MIPS的许可证持有者,为企业提供“自建”CPU程序。这项服务被称为 CoreWare,客户可以通过选择一系列构建模块来构建自己的 CPU 包[3]。CoreWare 库的一部分包括 “CW33300”模块,这是一个从 LSI LR33300 衍生出来的 CPU 内核,LSI 也将这种现成的 CPU 芯片商业化。 这项服务被称为CoreWare,客户可以通过选择一系列构建模块来构建自己的CPU包[3]。CoreWare 库的一部分包括 “CW33300”模块,这是一个从 LSI LR33300 衍生出来的 CPU 内核,LSI 也将这种现成的 CPU 芯片商业化。 CoreWare库的一部分包括“CW33300”模块,这是一个从LSI LR33300衍生出来的CPU内核,LSI也将这种现成的CPU芯片商业化。
现在,我要把这些说到哪里去呢? 原来,LSI的LR33300和CW33300是MIPS R3000A系列的二进制兼容版本。 它们的架构在某些方面略有不同,但编程接口(MIPS I ISA)保持不变。
最后,索尼公司委托LSI公司为其开发CPU包。 他们选择了CW33000,更改了一些位,并将其与其他模块组合在一起,形成了PlayStation主板上的芯片。
产品

由此产生的CPU内核运行频率为33.87 MHz,具有以下特点:
- MIPS I ISA:MIPS指令集的第一个版本。 其中,字长为32位,指令集包括乘法和除法指令。
- 32个通用寄存器和2个乘除寄存器: 这些寄存器也是32位的。 其中一个通用寄存器始终为零(
R0),这在RISC处理器中很常见。 - 32位数据总线: 在PS1中,数据总线分为两条总线。
- 主总线(32位)→连接MDEC和GPU。
- 子总线(16/8位) → 连接其他芯片和I/O。 该总线由总线接口单元桥接,还可以访问GPU和SPU的特殊端口。
- 32位地址总线: 最多可访问4 GB物理内存(即 RAM、内存映射I/O等)。
- 5级流水线:最多可同时执行五条指令(详细说明请参阅上一篇文章)。
- 4 KB指令高速缓存(Cache): 它也可以被“隔离”,允许程序直接操作指令缓存。
- 奇怪的是,这里没有数据缓存。 通常用于数据缓存的1 KB内存被映射到一个固定地址[2]。 这个区域也被称为Scratchpad(快速SRAM)。
为了做一些有意义的事情,索尼提供了2 MB的RAM供一般用途使用。 奇怪的是,他们在主板上安装了扩展数据输出(EDO)DRAM芯片。 这些芯片比典型的DRAM稍为高效,可获得更低的延迟。
接管 CPU
在某些情况下,任何子系统(图形、音频或CD)都需要快速处理大块数据。 然而,CPU并非总能满足需求。
因此,CD-ROM控制器、MDEC、GPU、SPU 和并行端口在需要时都可以访问专用DMA控制器。 DMA控制主总线并执行数据传输。 虽然仍需要CPU来设置DMA传输,但其传输速率要比依赖CPU快得多。
此外,请记住,一旦 DMA 启动,CPU 就无法访问主总线。 这意味着CPU将处于空闲状态,除非Scratchpad中的内容能让它保持忙碌!
补充内核
与其他基于MIPS R3000的CPU一样,CW33000支持多达四个协处理器的配置,索尼定制了三个:
系统控制协处理器
系统控制协处理器标识为“CP0”,是MIPS CPU上的一个常见模块。 在基于R3000的系统(如本系统)中,CP0控制高速缓存的实现方式。 因此,可以直接访问数据高速缓存(以“Scratchpad”的形式)和指令高速缓存(使用“高速缓存隔离”)。 控制协处理器还负责处理中断、异常和断点,后者在调试时非常有用。
等等,协处理器不是只能_扩展CPU_的功能吗? 为什么CP0与CPU紧密耦合?
事实上,R3000内核依赖系统控制协处理器才能使用许多组件,但这是否“合法”取决于对“协处理器”一词的解释。 根据MIPS的规定,协处理器并不是CPU的严格意义上的可选部件,它还可以指挥CPU的周围环境(高速缓存、中断等)。 因此,协处理器可以是系统不可分割的一部分。 在讨论与MIPS有关的系统时,这一点值得注意。
后来,基于R4000的系统将内存管理单元(MMU)和转译后备缓冲区(TLB)整合到了这个模块中,从而增强了它的功能并承担了新的角色。
几何变换引擎
“CP2”或几何变换引擎(GTE)是一种特殊的数学处理器,可加速矢量和矩阵计算。
虽然只能运行定点类型,但它仍能为 3D 图形提供有用的运算,例如:
- 矩阵或矢量乘法和加法;以及矢量平方。
- 透视变换(用于三维投影)。
- 两个或三个矢量的外积(后者用于剪切)。
- 许多使用不同参数的插值函数。
- 来自光源的深度提示和色彩值(用于照明和色彩操作)。
- Z值/深度平均值(我猜测这是用于“排序表”,更多详情请参见“图形”部分)。
您不必记住所有这些信息就能理解文章的其余部分! 请记住,GTE将负责图形流水线的第一阶段,如3D投影、照明和剪切。 这将有助于生成所需的数据,并发送到GPU进行渲染。
运动解码器
运动解码器(Motion Decoder),也称为“MDEC”或“宏单元解码器”,是 CPU 旁的另一个处理器。 这里,它将“宏单元”解压缩为GPU可以理解的格式。 宏单元是一种数据结构,其中包含与JPEG类似编码的图片。
MDEC一次解压8x8 24bpp像素的位图。 Walker的编程指南指出,MDEC每秒可计算9000个宏单元。 这样就能以30FPS的速度流式传输320x240像素的全动态视频 (FMV)。
DMA用于通过CD-ROM→RAM→MDEC发送压缩数据。 同样的路径在相反的方向上进行,不过在这种情况下,目的地是VRAM。
虽然该组件位于SoC内部并共享相同的数据总线,但它不是MIPS协处理器,因此CPU/DMA要通过内存映射访问它(而不是拦截指令)。
缺了个单元?
到目前为止,我们已经有了“CP0”和“CP2”,但“CP1”在哪里?这是为浮点运算单元(FPU)预留的,恐怕索尼没有提供。 这并不意味着CPU不能进行十进制运算,只是速度不够快(软件模拟的FPU)或过于精确(定点运算)而已。
游戏逻辑(涉及物理、碰撞检测等)仍可使用定点运算。 定点编码以固定的小数位数存储十进制数。 这意味着在某些运算后会损失精度,但请记住,这是视频游戏机,而不是专业的飞行模拟器。 因此,在精度和性能之间进行权衡是可行的。
顺便说一句,如果你想重温一下“定点”、“浮点”、“十进制”和“整数”等概念,我建议你看看Gabriel Ivancescu的文章[5]。
大量延迟
正如我们之前所见,CW33300是一款流水线处理器,这意味着它可以将多条指令排成队列,在不同阶段并行执行。 这极大地提高了指令吞吐量,但如果控制不当,就会导致流水线冒险,造成计算错误。
MIPS I架构就容易出现这种情况[6]:
- 控制冒险: 指令可能在不该执行时被执行。
- 数据冒险: 指令可能在更新前使用过期数据运行。

LW(从内存中加载字)、JAL(跳转和链接)和BNE(不相等时分支)后面都有一个延迟槽,以防止出现冒险。 红色标记的是填充指令(无用指令)。 蓝色标记的指令执行有意义的操作。因此,MIPS I CPU表现出以下行为:
- 任何跟随“分支”或“跳转”类型操作码的指令都会被无条件执行: 因此,开发人员必须在分支或跳转后手动在流水线中填充适度的指令(如
计算0+0),以减少冒险。 这些填充物被称为分支延迟槽。- 现代CPU将这一现象转化为优势:分支预测。 通过增加额外的电路来检测冒险,如果不满足分支/跳转条件,CPU就会丢弃新的计算。 但如果满足了,CPU就节省了一些时间。
- “加载”指令不会使流水线停滞,直到检索到的数据可用: 流水线的第二阶段(称为
RD或“读取和解码”)收集运算符[7],用于在第三阶段(ALU)执行计算。 第四阶段(MEM,源自“访问内存”(access MEMory))在内存(即主RAM、CD阅读器等)中查找数据。 现在,问题来了:当一条load(加载)指令从外部收集数据时,下一条指令已经获取了运算符。 这意味着,依赖于前一条load指令值的指令需要在中间进行填充,以便及时获取正确的运算符。
从示例中我们可以看到,一些延迟槽被有意义的指令填满,这些指令执行的计算不受冒险的影响。 因此,延迟槽并不总是意味着周期的浪费。
在解释了这些之后,你可能会问,为什么存在这些缺陷的处理器会被商业化。 关于RISC的一个理念是,CPU编程的负担从开发人员转移到了编译器。 特别是 MIPS,他们优先考虑制造高质量的编译器(包括汇编器)来配合他们的新CPU[8]。 因此,开发人员可以使用更高级别的语言(例如C语言),而工具链则负责处理冒险(通过重新编排指令来填补空白;或添加无用的填充指令作为最后措施)。 因此,总而言之,虽然我不喜欢看到CPU充满气泡,但我认为MIPS以非常巧妙的方式解决了这个问题。
图形
概括地说,图形处理流程的很大一部分是由 GTE 完成的。 其中包括透视变换(利用摄像机的透视将3D空间投射到2D平面上)和光照。 处理后的数据将被发送到索尼专有的GPU上进行渲染。
硬件组织
系统配备1 MB的VRAM,用于存储帧缓冲区、纹理和GPU渲染场景所需的其他资源。 CPU可以使用DMA填充该区域。
配备的芯片(VRAM)是双端口的,就像Virtual Boy的一样。 VRAM使用两条16位总线,可在CPU/DMA/GPU和视频编码器之间同时访问。
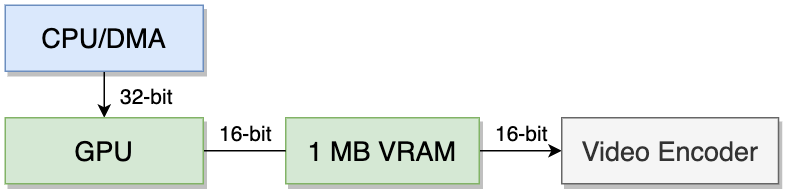

不过在这款游戏机的后期版本中,索尼改用了SGRAM芯片(使用单独32位数据总线的单端口选项)。 嘘!…… 好吧,公平地说,每一种都有其优点和缺点。 可以肯定的是,由于时序上的差异,后来的游戏(如喷气摩托3(Jet Moto 3))在基于VRAM的系统上运行时,会出现图形卡顿的现象。 如果你想了解详情,Martin Korth的“Nocash PSX规格”记录了不同的时序等信息[9]。
绘制场景
如果您一直在阅读世嘉土星的文章,让我告诉您,这款GPU的设计要简单得多!
现在,我主要以Insomniac的小龙斯派罗:龙年(Spyro: Year of the Dragon)为例,向大家展示如何绘制场景。 请注意,这款游戏的内部分辨率过于狭窄(292x217像素),导致我无法清晰地剖析游戏的每个阶段,因此我将其放大了一些,以方便演示。 如果你好奇,这里有一个 原始比例的样本 。
指令
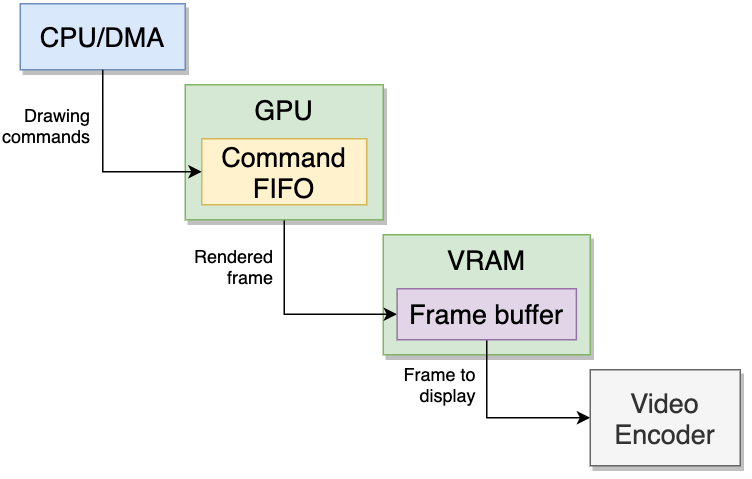
首先,CPU通过向内部64字节FIFO缓冲区填充指令(最多三条),向 GPU 发送几何数据(顶点)。 这些命令可能要求GPU渲染某些内容、更改设置或操作VRAM。
从本质上讲,渲染命令说明了绘制基元的方式和位置。 GPU可以单独绘制线条、矩形和三角形,后者是构成丰富3D模型的基本要素。
一旦接收到几何图形,就会进行剪切,以跳过对不可见多边形(位于摄像机视角之外)的操作。
基元的位置用指向帧缓冲区的 X/Y 坐标系来表示。 PS1的GPU采用整数坐标模型,每个坐标对应一个像素的中心点(称为采样点)。 换句话说,没有小数坐标。
可见性方法

与竞争对手一样,PS1也不具备任何解决可见性问题的硬件功能。 不过,GPU通过提供一个排序表来处理排序的多边形: 这是一个专用表格,其中每个条目都使用深度值(也称为 “Z值”)进行索引,并包含GPU命令所在的地址[11]。
CPU首先需要手动对多边形进行排序,然后将它们引用到表中正确的条目中。 最后,CPU会命令DMA将表格发送到GPU。 这一过程将使GPU能够以正确的顺序渲染几何图形。
此外,还提供了多个DMA函数,以协助CPU和GPU创建和遍历该表。
光栅化

一旦命令被GPU解码,就需要将接收到的几何图形(顶点)转换为像素。 这将使系统能够应用纹理映射和特效,并最终将其显示在二维面板(电视或显示器)上。 为此,GPU会分配一个像素矩阵作为工作区,这就是所谓的帧缓冲区。 与更复杂的世嘉土星相比,GPU 只需要一个帧缓冲器。
光栅化器是负责将向量转换为线条、三角形或矩形,然后再转换为像素的单元。 现在,这一过程因所需的基元不同而大相径庭[12]:
- 三角形是最复杂(也是用途最广)的类型,可以制作纹理和阴影。
- 直线的绘制速度较快,但对于纹理表面来说自然不可行。。 它们仍然可以着色
- 矩形也比较快,但只能拿来制作最多容纳256x256像素的精灵(更大的矩形会重复精灵的图形)。 即便如此,它们也不提供仿射变换(X/Y 翻转除外)、着色或特效。 我怀疑这样做是为了帮助 2D 游戏的实施。
对于三角形这个唯一能用来制作纹理的多边形,光栅化器将:
- 抓取每个三点顶点并计算边缘。 这样就形成了一个三角形。
- 分析三角形区域,确定它们占据了帧缓冲区的哪些像素。 只有覆盖采样点的多边形部分才会变成像素。
生成的像素不会立即写入帧缓冲区。 相反,它们会被发送到流水线的下一阶段进行进一步处理,我们将在下面的段落中看到。
着色器

为了在三角形或线条上应用光照效果,GPU提供了两种算法:
- 平面着色: 每个基元都有一个恒定的光照度。
- 高洛德(Gouraud)着色: 每个基元的顶点都有自己的光照度。 然后,每个点之间的亮度会自动插值。
- 可以想象,这种类型比平面阴影效果更逼真。
之所以有这种选择,是因为平面着色每秒填充的多边形数量是高洛德着色的~2.5倍,因此优化哪些多边形需要比其他多边形更逼真的着色非常重要。
纹理
三角形表面还可以与纹理(2D位图)混合,生成最终效果。
GPU执行逆纹理映射,即 GPU 遍历每个光栅化像素,并在纹理贴图中查找其对应的像素(称为纹理元素(Texel))。 纹理元素是通过线性插值纹理贴图(在VRAM中找到)来计算的,以符合多边形的形状。 用于插值的程序称为“仿射纹理贴图”,这种技术只使用2D坐标(X-Y值),而忽略了用于透视的第三个坐标(Z或“深度”)。
由于纹理贴图很少具有光栅化多边形的精确尺寸,因此可能会出现混叠(不正确的结果)。 这表现为不必要的失真,例如缺失或放大的纹理。 为了解决这个问题,先进的GPU采用纹理过滤技术来平滑(插值)颜色的突然变化。 现在,PS1的GPU没有实现任何过滤功能,因此它采用了一种名为近邻的算法来校正比例,而不会平滑结果。 这种算法速度非常快(而且便宜),但这也解释了为什么纹理模型看起来会“方方正正”。
GPU还包含以下可供使用的特效(在三角形上):
- 半透明: 模拟光线穿过多个纹理。
- 抖动: 柔化颜色的突然变化,同时保持相同的调色板。
值得一提的是,PS1恰好擅长这些效果!
剩余步骤
完成后,GPU会将像素写入VRAM中的帧缓冲区,然后由视频编码器接收并播放到屏幕上。
设计
让我们从这些理论中解脱出来。 这里有一些为3D时代从头开始设计的游戏角色的例子,它们是可交互的,所以我鼓励你去看看!
| 线框 | 表面 | 纹理 |
 | ||
| 点击启用交互功能 | ||
413个三角形
| 线框 | 表面 | 纹理 |
 | ||
| 点击启用交互功能 | ||
732个三角形
玩转 VRAM
利用可用的 VRAM(整整 1 MB),我们可以分配一个1024×512像素、16位色彩的超大帧缓冲区,或者一个960×512像素、24位色彩的逼真帧缓冲区–让我们可以绘制任何游戏都曾展示过的最佳帧…… 这听起来很令人印象深刻,对吧? 不过,这也引发了一些问题:
- 这些尺寸必须按照标准化的定义(即 480 NTSC、576 PAL)重新缩放,这样视频编码器才能将其播放到消费者的电视上。
- 如果没有任何空间留给其他素材(如纹理、色彩表等),GPU 又怎么能画出像样的东西呢?
- PS1的GPU最多只能绘制640×480像素和16bpp颜色的帧缓冲区。
好吧,那就用16bpp的640x480缓冲区来代替,这样就有424 KB的VRAM用于绘制材质。 到目前为止还不错吧? 同样,这样的分辨率在 CRT 显示器上可能还不错,但在 90 年代每个人家里都有的那种电视上就不那么明显了。 那么,有没有办法优化帧缓冲器呢? 引入可调节的帧缓冲器。

从本质上讲,该游戏机的GPU不需要通过使用“不受欢迎”的分辨率来浪费宝贵的VRAM,而是允许减少帧缓冲区的尺寸,从而有效地增加其他资源的可用空间。 在“Gears Episode 2”[13]中,Halkun展示了一种将640x480帧缓冲区分为两个320x480帧缓冲区的设置,然后依靠一种名为“翻页”(page-flipping)的技术同时渲染多个场景。
翻页技术包括在游戏需要时,在两个可用的帧之间切换显示位置,使游戏可以在显示一个场景的同时渲染另一个场景。 因此,可以隐藏任何闪烁效果,并改善加载时间(玩家肯定会对此表示赞赏!)。
总体而言,Halkun的布局仅消耗600 KB的VRAM。 剩下的部分(424 KB)可用于存储颜色查找表和纹理,再加上2 KB的纹理缓存,这样的设置非常方便高效。
最后值得一提的是,VRAM可以同时使用多种颜色深度进行映射,这意味着程序员可以在24bpp位图(例如FMV框架使用的位图)旁边分配一个16bpp的帧缓冲区。 这是另一项有利于进一步优化空间的功能。
机密与限制
尽管PS1的架构非常简单合适,但问题还是接踵而至。 令人惊讶的是,某些问题却能通过非常巧妙的变通方法得到解决!
扭曲的模型/纹理
众所周知,用于处理几何图形和应用纹理的例程存在一些误差。
首先,光栅处理器只能处理像素单位:虽然顶点坐标是整数,但计算出的三角形边缘可能只占一个像素的一小部分。 然而,光栅化器只会在三角形区域覆盖像素采样点的情况下绘制像素,而不会跟踪所占的部分[14]。 这就带来了一些问题:
- 模型的外部边缘在轻微移动时会突然跳动。
- 网格中的三角形(共享相同的顶点和边缘)会“争抢”绘制相同的像素。 有了排序表,GPU将按照“先到先得”的原则进行绘制,这可能会导致三角形交叉点在轻微移动时闪烁或重叠。
解决这一问题的方法通常是采用亚像素分辨率(sub-pixel resolution),光栅化器从中跟踪每个三角形区域所占像素的分数[15]。 因此,可以添加抗锯齿方法来缓和锯齿状边缘或颜色的突然变化。
接着,排序表要求开发人员/程序按照正确的顺序显示几何图形。 在某些情况下,为了提高性能,执行的计算依赖于过多的近似值。 这可能会导致本应显示的表面闪烁或被遮挡。
此外,设置低分辨率的帧缓冲区可能会放大所有这些混叠问题。
最后,正如大家所知,仿射变换没有深度感,当摄像机靠近模型并垂直于观看者时,用户的感知可能会被混淆[16]。 这种效果也被称为纹理扭曲(texture warping)。 因此,一些游戏采用了曲面细分(将大多边形分割成小多边形)来减少失真,而另一些游戏则直接交换纹理,改用纯色。 一般来说,GPU最终会通过实现透视校正来解决这一问题,即使用深度值对纹理进行插值。
自相矛盾的主张
如果你查看其他技术频道或论坛,你会发现关于PS1摇摆/扭曲/失真效果的其他解释。 其中一些与我之前的解释不谋而合,而另一些则会提出不同的观点。 因此,我想就以下说法不准确的原因谈谈我的看法:
模型/纹理晃动是因为缺少FPU
FPU 并不决定计算机是否能进行小数运算。 PS1和其他没有FPU的计算机一样,仍然可以进行定点运算。 此外,使用软件仿真,浮点数也可以计算(只是速度较慢)。 总之,FPU只是加速器,不要将其与ALU(算术逻辑单元,CPU中执行算术运算的关键部分)或十进制数混为一谈。
GPU 的整数坐标系导致模型/纹理晃动
采用整数坐标系是降低GPU计算成本的常用方法。 正是因为没有采用亚像素分辨率,这才成为一个显而易见的问题。 总而言之,如果光栅处理器能够计算三角形所占像素的比例,那么就可以使用抗锯齿技术来平滑色彩的突然变化。
缺乏混合映射导致纹理扭曲
实施反纹理映射的GPU(如本机)会出现一种称为“欠采样”的测量误差(一个像素被映射到多个纹理)。 因此,这会产生混叠(错误的结果)。 在渲染距离摄像机较远的几何体时,这种现象非常明显。 为了解决这个问题,现代纹理贴图程序采用了“三线性过滤”技术,即使用存储在不同比例的相同纹理软化色元(mipmaps),并在两者之间进行一些插值。 总而言之,mipmapping是一种解决混叠问题的方法。 它是一种仿射纹理贴图(缺乏透视校正),在三点表面上进行纹理插值,而不考虑深度。 因此会产生“扭曲”效果。
缺乏Z缓冲导致模型/纹理闪烁
带有Z缓冲的GPU可在硬件层面上解决可见表面的确定问题。 PS1依赖于排序表,这意味着开发人员负责确定哪些几何体位于其他几何体之前。 总之,任何显示闪烁三角形的模型都是由排序例程(软件)引起的,因此可以通过相同的软件来解决。
预渲染的图形

现在让我们来谈谈“好”的功能…
如果一款游戏想要获得比GPU所能提供的更逼真的场景,一个可行的办法就是堆叠两个三角形,然后使用运动解码器在上面输入预渲染的电影画面。 FMV视频会占用大量空间,幸好CD-ROM为此做了准备。
有些游戏专门依靠它来合成背景,而且老实说,在显像管电视上看这些视频还是很有说服力的,但显然,具有升分辨率功能的现代模拟器很快就能分辨出来。
视频输出
该控制台的第一版带有以下端口,可传输数量惊人的视频信号:
- RFU DC:这个接口很快就被移除了,它本来是用来连接射频调制器的。
- RCA:提供复合视频接口。
- S-Video:提供Luma+Sync(组合)和Chroma。
- AV多路输出: 提供除RFU以外的所有前述信号,以及RGB和一条5V+电源线。
后来的控制台改版取消了这些端口,最后只剩下 “AV多路输出”。
音频
索尼标志性的声音处理单元(SPU)可以解决这个问题。 该芯片支持大量24通道16位ADPCM采样(著名的PCM采样的更高效版本),采样率为44.1 kHz(音频CD质量)。
该芯片还具有以下功能:
- 音高调制: 顾名思义,游戏可以自动改变采样音高,而无需额外存储。 这对音乐排序非常有用。
- 频率调制: 可指定声音来改变其他声音的频率。 类似于调频合成。
- ADSR包络: 这是一组可用于振幅调制的属性。
- 循环: 指示系统重复播放一段音频。
- 数字混响:在特定的氛围中模拟正在播放的样本,让播放者身临其境。
512 KB DRAM(称为“声音RAM”)用作音频缓冲区。 CPU(仅通过 DMA)和CD控制器可访问该内存。 虽然游戏只有508 KB可用来存储采样,但SPU会保留其余部分用于处理音频CD音乐。 如果激活混响功能,内存容量还会进一步减少。
CD控制器还能将采样直接发送到音频混音器,而无需经过音频缓冲区或 CPU 干预。 采样还可以使用“XA”编码进行压缩,SPU可以对其进行即时解码。
流媒体时代
与土星类似,游戏不再依赖于音乐排序或预定义波形,而且由于CD-ROM介质的存储量大,开发人员可以存储完全制作好的采样,然后直接将它们流式传输到音频芯片。
I/O
有两个I/O 端口(串行和并行)可供附加设备使用。 不过,在后来的游戏机版本中,这些端口已被移除,原因是它们未被采用,而且有可能被用来破解复制保护系统。
CD子系统
控制CD驱动器的区块是一个有趣的区域,你可以把它想象成PlayStation内部的一台独立电脑。
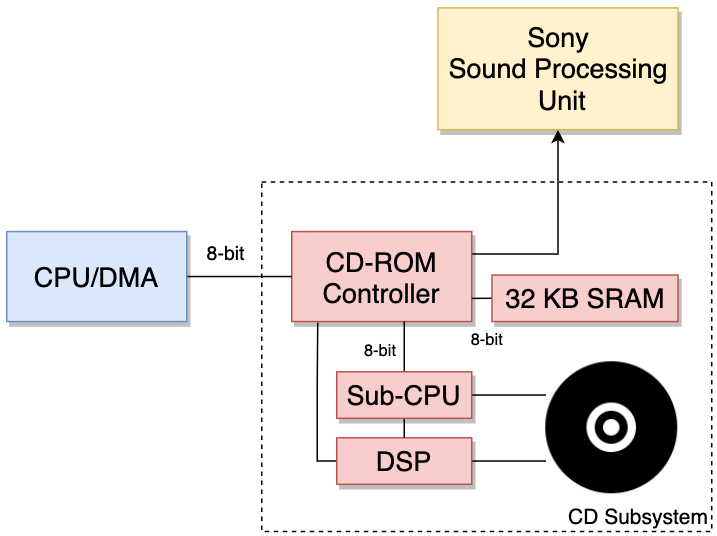
该子系统由以下部分组成
- 数字信号处理器(DSP):控制电机和激光器,并处理来自激光器的射频信号。
- 一个子CPU: 由摩托罗拉68HC05微控制器、512 B RAM和16 KB ROM组成的中央处理器套件[17]。 简而言之,子CPU运行存储在ROM中的本地程序,并控制DSP。 子CPU程序执行复制保护措施,无论主CPU“喜欢与否”,这些措施都会被执行。
- CD控制器: 它是CD子系统和游戏机其他部分之间的中间人,接收主CPU的命令(以先进先出(FIFO)的方式),并在某些事件发生后触发中断。 作为控制器,该芯片与副CPU通信,并从DSP接收CD数据。 此外,控制器还包含一个DMA单元,并与SPU相连,可直接串流音频。
- 32 KB的SRAM与控制器相连: 这大概是用作从光盘读取数据的缓冲区。
这个子系统有点像每个人家里都有的普通CD读取器,只是索尼在子CPU程序中进行了调整,以执行反盗版检查。
前端端口
控制器和存储卡插槽在电气上是相同的[18],因此每个插槽的地址都是硬编码。 此外,索尼还改变了端口的物理形状,以避免发生意外。
与这些设备的通信是通过串行接口完成的。 从游戏机发出的命令将传递到两个插槽中的一个(“存储 卡0”和“控制器0”,或 “存储 卡1”和“控制器1”)。 然后,两个附件都将以其独一无二标识符作出应答,这将使游戏机从现在起专注于特定类型的设备(存储卡或控制器)。
操作系统
系统包括一个512 KB的ROM,其中存储了一个“BIOS”。 该程序提供多种服务,包括启动程序、显示用户shell以及提供一系列I/O例程 [19]。
BIOS/ 内核
BIOS是游戏的关键依赖程序,因为该程序可从CD驱动器启动游戏。 此外,BIOS还是与游戏机硬件交互的“中间人”。 后一种方法类似于IBM在其IBM PC BIOS中采用的方法,即鼓励开发人员使用标准中断表(包含I/O例程),而不是依赖于平台的I/O 端口。
尽管如此,PS1的BIOS还是提供了一些例程,例如
- 光驱命令。
- 文件系统操作(从 CD-ROM 和存储卡)。
- 多线程。
- 标准C函数(字符串操作、内存操作等)。
由于BIOS ROM的访问速度非常慢(与8位数据总线相连),API被打包成内核的形式,并在启动时复制到主RAM中。 因此,64 KB的主RAM是为内核预留的。 顺便说一句,内核也被称为PlayStation OS。
启动过程
CPU的复位向量位于0xBFC00000,指向BIOS ROM。


与世嘉土星的启动过程类似,PS1在接通电源后会:
- 查找BIOS ROM并执行例程初始化硬件。
- 加载PlayStation操作系统。
- 显示高光屏。
- 如果插入了CD,CD-ROM控制器会检查CD是否为正版:
- 是→控制器允许读取内容。
- CPU将查找“SYSTEM.CNF”并继续执行。
- 不是→CPU将显示错误信息。
- 是→控制器允许读取内容。
- 如果没有插入 CD,CPU将显示shell界面。 现在由用户控制。
shell界面是一个简单的图形界面,用户可以复制或删除存储卡中的保存内容,或播放音频CD。
游戏
就像世嘉土星和其他改用CD介质的游戏机一样,现在游戏也有了一套新的设施: 大容量存储空间(640 MB)、良好的音质和归功于2倍速光驱带来的“不慢”的读取速度。
如果您想了解光盘(CD)的工作原理,我已在世嘉土星文章中做了简要说明。
开发生态
官方SDK提供了与BIOS例程链接的C库,用于访问硬件。 如果你想知道,其实这是帮助在各种平台上模拟PS1的主要因素。
除了SDK,索尼还分发了DTL-H2000等专用硬件:一块双插槽ISA卡,包含PS1的内部结构和输入/输出[20],以及用于调试的额外电路。 该卡可以访问主机的硬盘驱动器,并能不受限制地执行PS1软件。 相应的软件需要一台安装了Windows 3.1或Windows 95的PC。
反盗版/锁区
大家可能都知道,要从光盘中获取数据,需要使用激光束来检测光盘轨道上的凹坑和平地。
现在,传统光盘并不是100%平整的,它们的轨道经常会有微小的波动。 这些缺陷在读取数据时是完全无法察觉的,因为激光可以在读取时自动校准。
这正是索尼复制保护方法的基础: 子CPU可以读取光盘上的目录(Table of Contents,TOC),这些目录是用一种预定义的频率刻制的,非正式地称为摇摆槽(Wobble Groove),这种频率只在母盘制作过程中使用,无法通过传统刻录机复制。 TOC位于光盘的内部(称为“导入”(Lead-In)区),指示激光如何在整个光盘中导航[21]。 此外,作为一种容错机制,它还会重复多次。
在 PS1 游戏的 TOC 中,嵌入了以下字符串之一:
- SCEA → 美国索尼电脑娱乐。
- SCEE → 欧洲索尼电脑娱乐。
- SCEI → 日本索尼电脑娱乐。
可以想象,光驱也会使用这种技术进行锁区。
击败
另一方面,这种检查只在开始时执行一次,因此在通过检查后手动交换光盘可能会破解这种保护……并有损坏光驱的风险。 后来,一些游戏自己动手,经常在游戏中重新初始化硬盘,以便再次执行检查,这样做是为了防止用户使用 “交换技巧”。
另外,还可以在游戏机中焊接编程了模拟摇摆信号的微小电路板。 这些电路板被称为改机芯片(Modchips),虽然在法律上有问题,但却非常受欢迎。
报复
模拟器的使用对发行商来说也是一种威胁。 因此,一些游戏包含了自己的检查(主要是校验和),以打击任何类型的未经授权的使用或修改。
我听说其中一种检查方法是故意重新初始化光驱,然后让它读取无法通过摇摆槽检查的特定扇区。 如果这样做还是成功解锁了光驱,那么游戏(仍然保存在RAM中)就会很高兴地显示其反盗版材料。 请注意,这种方法也会影响使用正版游戏的改装游戏机。
后来,索尼提供了一个名为Libcrypt的库,利用两种方法加强了复制保护措施[22]:
- 从硬件方面来说,扇区的校验和存储在光盘的子通道中。
- 光盘子通道传统上存储元数据,主要用于引导光驱。 用户无法访问这些子通道,传统的光驱也很少允许手动写入这些子通道。
- 在软件方面,游戏的不同点都嵌入了一组例程,用于获取校验和值并将其与其他值混合。 这样做的目的是为了减少模拟器和改机芯片的影响。



{kind=link}